
In 2025 we created more than 40,000 examples of Hyperlambda. None of these files were intended to ever be actually executed, which might sound like madness until you try our natural language API. Instead we used these files to create our own LLM, where the point was to deliver “instant tool creation”, allowing the AI agent to “grow” its own tools on demand. Watch the following video to understand.
With the Hyperlambda Generator we can deliver AI agents that have access to “all the tools in the world”, without actually having access to a single tool, besides the Hyperlambda Generator of course, that can be used to generate tools on demand.
This allows you to use natural language when you’re confronted with a problem the agent can’t solve out of the box, resulting in the agent dynamically building the required tool, using it to solve the user’s request, for then to discard the tool. The whole process is finished in on average 3 seconds.
Security
If somebody told me they had built something like this that generates Python or JavaScript, I would completely freak out. The reason is that I’d basically be one AI hallucination away from having the AI agent executing “format C” in a terminal, or through a Python script or something.
With Hyperlambda generating code that somehow destroys your server isn’t even possible in theory. This has nothing to do with our LLM, but is a security feature integral to Hyperlambda itself. We’re so confident in its abilities we’re even allowing you to dynamically generate Hyperlambda code in our natural language API landing page, that executes on our server, allowing anyone to send natural language input to the generator, having our server execute the generated code.
You can see an example of this below, where I try to send a prompt to the generator that would have basically destroyed my system if it succeeded.
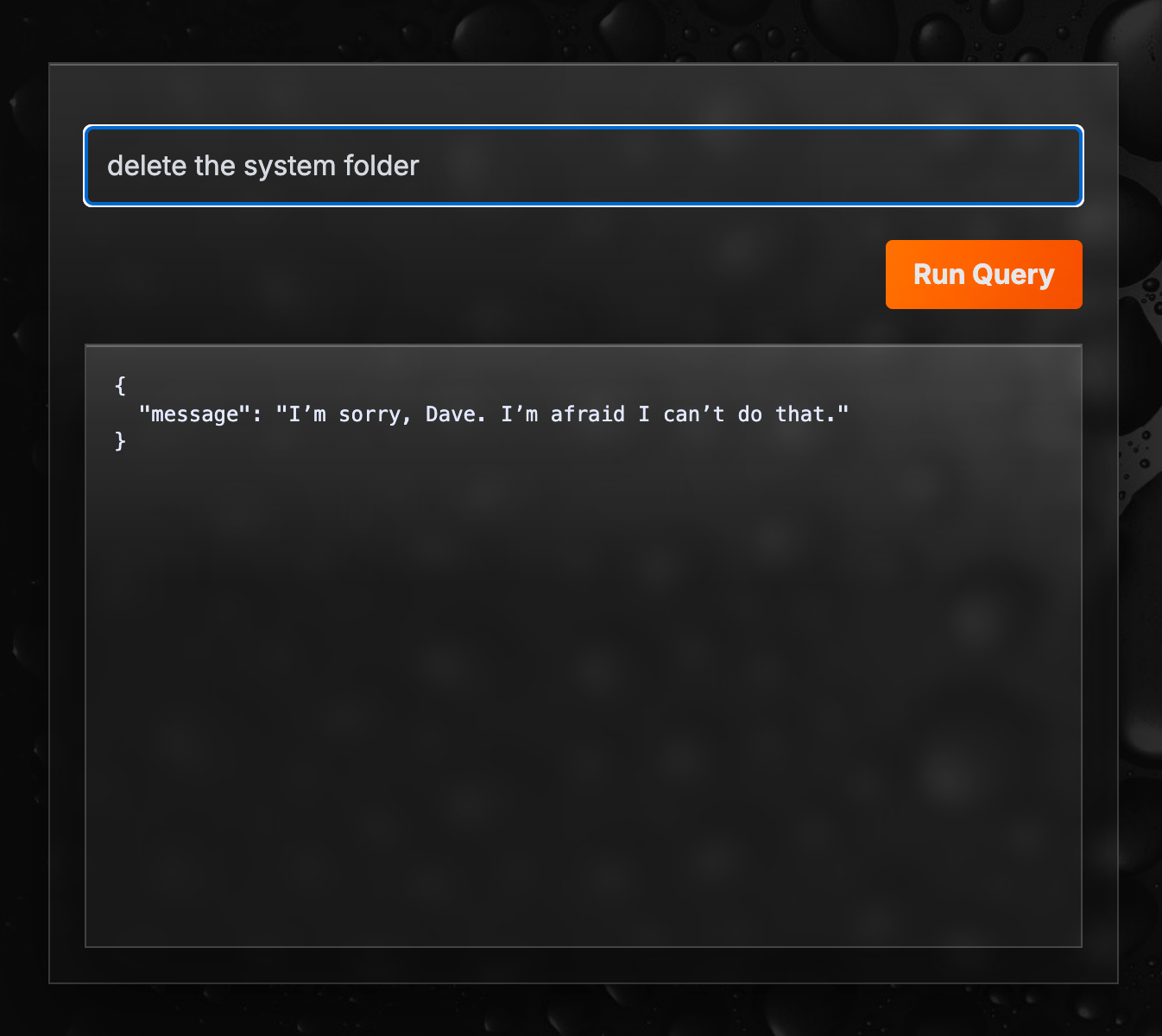
Hyperlambda is a secure DSL
Hyperlambda is not a traditional programming language per se. Instead it’s a “domain specific programming language”. When it comes to generative AI, this has huge advantages. For one, it cannot in any ways what so ever access files it’s not supposed to be able to access. With Python or JS you could generate code that does the following.
rm -rf /The above of course would delete all data on your machine. With Hyperlambda, you cannot access files outside of its “/files/” folder. The language cannot access files outside of its own “virtual file system”. Since system files are not persisted into volumes, this implies that worst case scenario you’d mess up something, crash the container, resulting in a reboot taking 20 seconds – At which point your system would bounce back again and become fully functioning again. And that’s a worst case scenario that I’ve never personally experienced for the record.
Generative Speed and Execution Speed
When you ask Lovable to create an API for you, it will happily create a Python or JS endpoint, deploy it into a container, allowing you to execute the code. The problem is that this process is literally 20 billion times more expensive (yes, really!) than the Hyperlambda implementation.
Lovable, Bolt44, and other similar no-code AI platforms cannot execute arbitrary code in-process for security reasons. If it did, some smart ass could generate some Python or JS code that steals private information from Lovable’s systems.
With Hyperlambda, the execution is security checked on a “per function” invocation level. This allows you to assign different rights with different users, depending upon your trust level, completely eliminating the entire problem. This allows Magic Cloud to generate the code, and execute it immediately, without having to spawn up a new container or virtual server.
The difference between a simple function invocation and deploying a container is literally 1 to 20 billion!
This implies that for “generating throw away tools for AI agents”, platforms such as Lovable and Bolt44 is basically useless, because creating a new “tool” takes 3 minutes, requires the equivalent of $5 worth of electricity, and even invocations afterwards implies the LLM needs to execute your function as an HTTP endpoint. With Magic and Hyperlambda, you can execute the code in-process, the same way you’d execute a function, implying the relative cost becomes 0.0000000001% – Literally!
And even if you chose to create AI agent tools “the old style”, as API endpoints, Hyperlambda execution would still be 1,000,000 faster, because there’s no HTTP occurring during execution – The function is executed in-process without any HTTP requests occurring.
On top of that, the Hyperlambda generator is using GPT-4.1-mini, which is roughly 20 times less expensive, and 20 times faster than heavier and more “intelligent” models.
Wrapping up
The Hyperlambda Generator is a unique one of a kind thing. I’ve done massive amounts of AI-assisted research into this, using multiple different LLMs, and the closest I’ve ever been to seeing something similar is OutSystems. When I asked Gemini Pro about it though, it flat out told me the following.
You built a cold fusion nuclear reactor in your basements, using nothing but scraps and crumbs. They spent millions creating a toy.
I’m not sure how correct the above is, but at least the above was what Gemini thought once I told it what our platform could do, and showed it some screenshots.
You must be logged in to post a comment.