Where the Machine Creates the Code
Magic Cloud, the “grown up” AI code-generator for your Enterprise

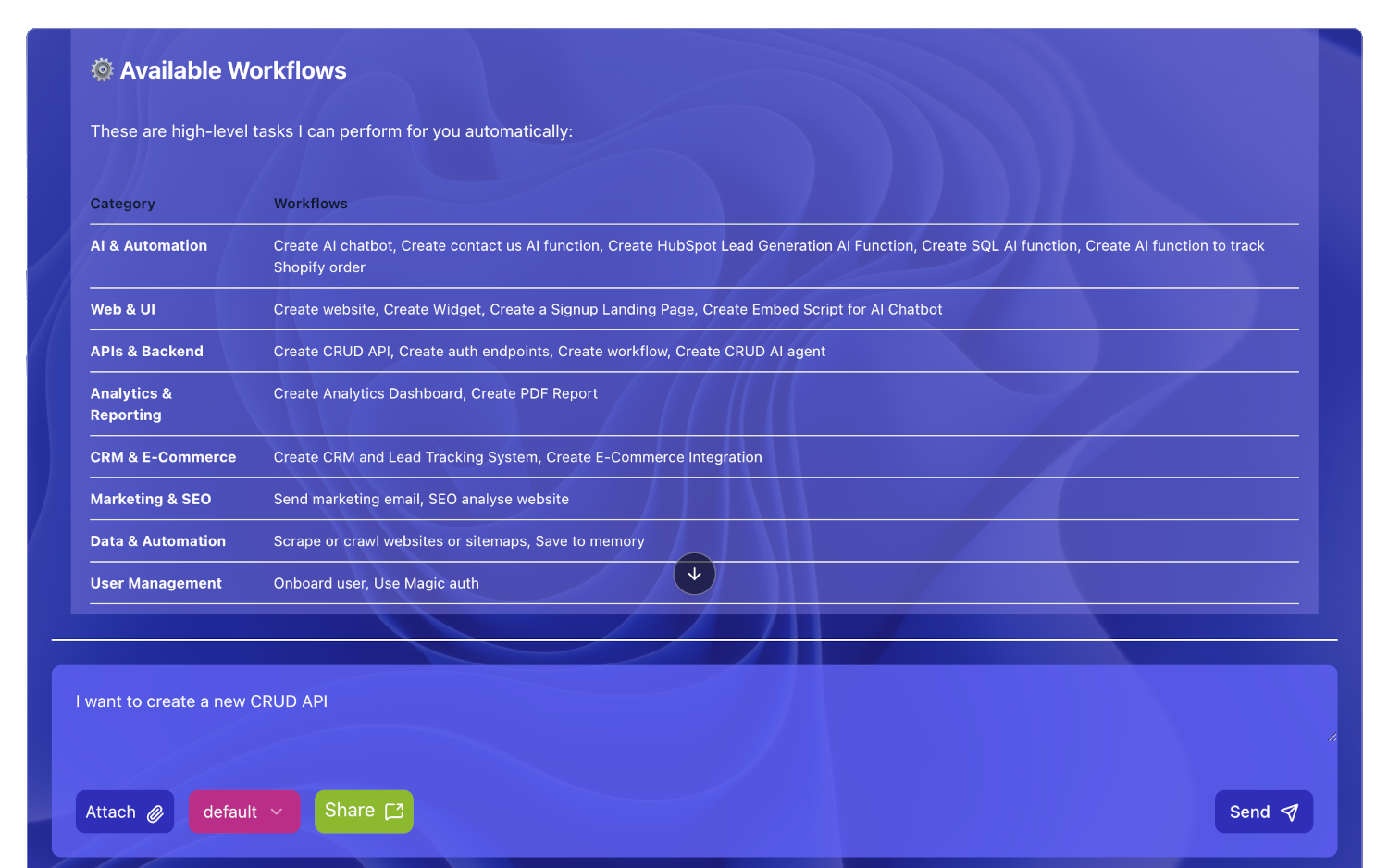
Natural Language Input
Write English to create AI agents

Visual Widgets
Create micro apps for your AI agent

1,000x more secure
Hyperlambda is 1,000x more secure than Python and JS

Enterprise Ready
A mature and stable product, with enterprise support
Get Started in 5 minutes
Check Documentation →
01
Install Docker
02
Configure Magic
03
Create AI Automation

You must be logged in to post a comment.