Category: magic
-

There are only two things that can go wrong related to ASI, and these are as follows; Every time somebody… Read more
-
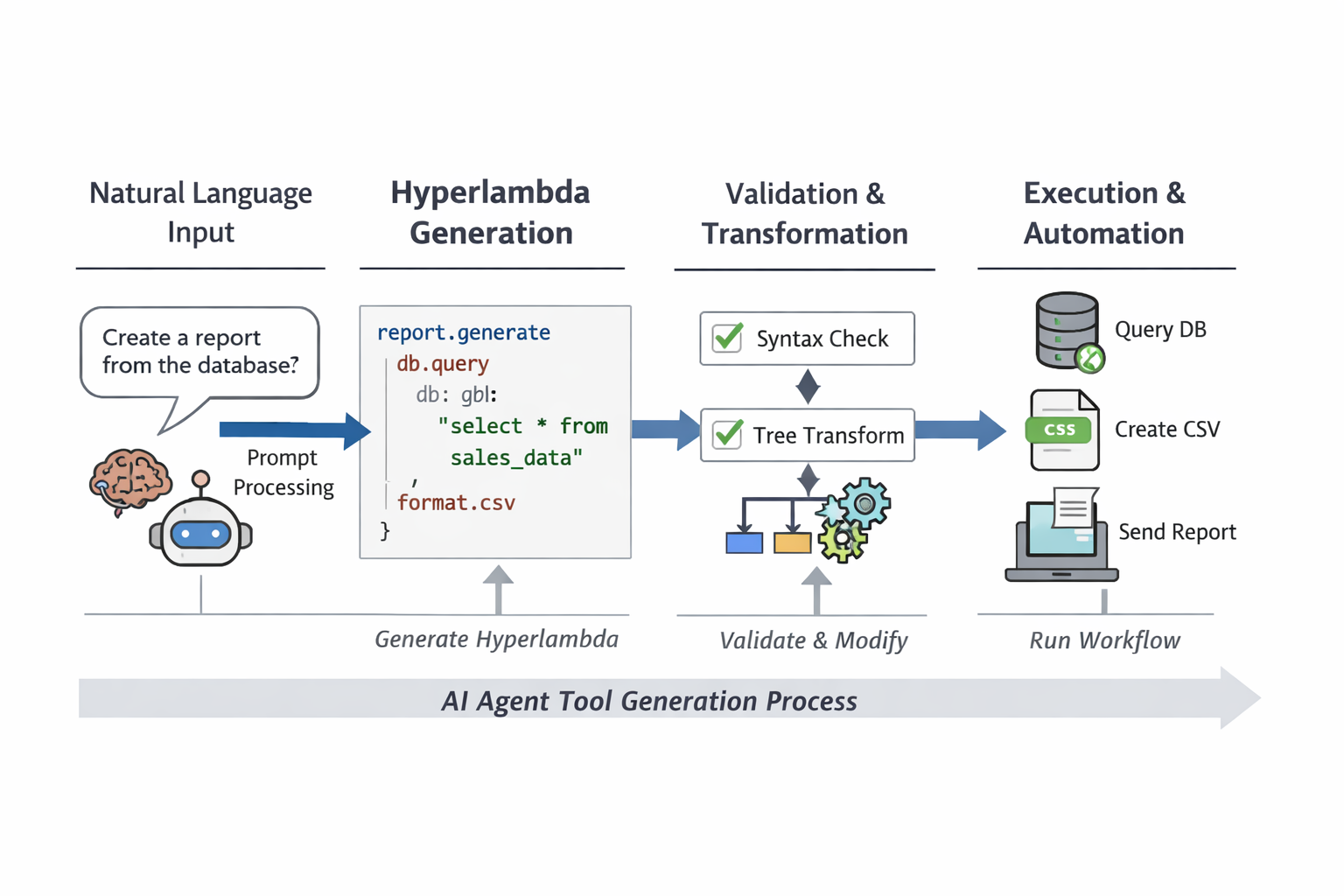
Hyperlambda is best understood as a tree-based, declarative, event-driven DSL designed to express agent tools, workflows, API logic, and automation as data structures that are… Read more
-

In 2025 we created more than 40,000 examples of Hyperlambda. None of these files were intended to ever be actually… Read more
You must be logged in to post a comment.